(ONECMS) - Cách The New York Times duy trì cơ sở dữ liệu về các ca nhiễm và ca tử vong do coronavirus tại Mỹ khi chắp vá dữ liệu từ các cơ quan y tế địa phương.



Tính đến nay, The New York Times đã thực hiện hơn 10 triệu yêu cầu trên toàn thế giới đối với dữ liệu đã được lập trình về đại dịch Covid-19. Dữ liệu chúng tôi đang thu thập là ảnh chụp nhanh hàng ngày về xu thế và dòng chảy của vi-rút, bao gồm dữ liệu cho mọi tiểu bang và hàng nghìn quận, thành phố và mã ZIP của Hoa Kỳ.
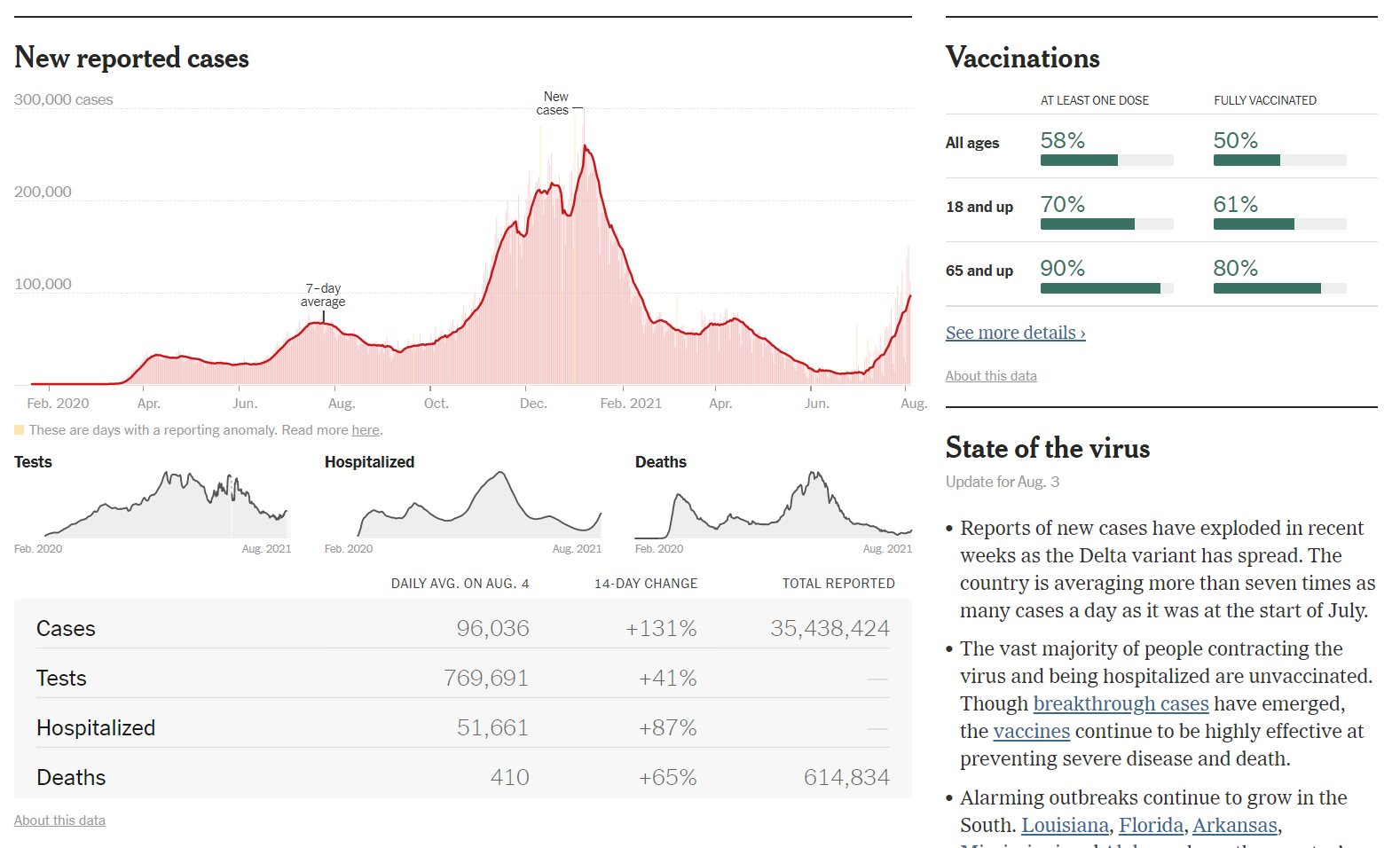
Bạn có thể đã thấy các phần dữ liệu này trong các bản đồ và đồ họa hàng ngày mà chúng tôi xuất bản tại The Times, cung cấp tổng số tích lũy và xu hướng trong 14 ngày giúp người đọc thấy được mức độ rủi ro và bùng phát tại địa phương của họ. Kết hợp lại, các trang này là bộ sưu tập được xem nhiều nhất trong lịch sử của nytimes.com. Chúng là một thành phần quan trọng của loạt bài về Covid-19 đã giành được Giải thưởng Pulitzer năm 2021 cho Dịch vụ Công của The Times.
Về mặt nội bộ, độ sâu và bề rộng của dữ liệu là một công cụ báo cáo vô giá, giúp chúng tôi kể những câu chuyện từ những trường hợp đầu tiên ở Hoa Kỳ, sự tàn phá của làn sóng trong mùa đông và những tin tốt lành đầu tiên khi vắc-xin bắt đầu được tung ra.
Dự án theo dõi coronavirus của Times là một trong số những nỗ lực đã giúp lấp đầy khoảng trống trong hiểu biết của công chúng về đại dịch do thiếu phản ứng phối hợp của chính phủ. Một trong số đó là Trung tâm Tài nguyên Coronavirus của Đại học Johns Hopkins, nơi đã thu thập dữ liệu của cả trong nước và quốc tế. Dự án Theo dõi Covid tại Đại Tây Dương đã điều động một đội quân tình nguyện viên để thu thập dữ liệu của các tiểu bang của Hoa Kỳ, ngoài dữ liệu thử nghiệm, nhân khẩu học và cơ sở chăm sóc sức khỏe, mỗi dữ liệu đều bao gồm những thách thức phương pháp luận hóc búa. Các dự án dữ liệu công khai này đã cung cấp một bộ nguồn bổ sung và cần thiết để đưa tin chuyên sâu.
Tại The Times, công việc theo dõi coronavirus của chúng tôi bắt đầu với một bảng tính Google Sheet duy nhất.
Vào cuối tháng 1 năm 2020, Monica Davey, một biên tập viên của National Desk, đã yêu cầu Mitch Smith, một phóng viên có trụ sở tại Chicago, bắt đầu thu thập thông tin trong một bảng tính của Google về từng trường hợp riêng lẻ của Hoa Kỳ về Covid-19. Mỗi trường hợp một hàng, được báo cáo tỉ mỉ dựa trên các thông báo công khai và được nhập bằng tay để kể câu chuyện của một người bị nhiễm vi rút, với các chi tiết như tuổi, vị trí, giới tính và tình trạng.
Khi đó, chúng tôi biết rất ít về khả năng lây lan của vi rút, vì vậy, việc theo dõi từng ca sớm của chúng tôi tuân theo một mô hình lỏng lẻo được thiết lập trong tòa soạn trong các đợt bùng phát vi rút khác. Số ca Covid-19 trong những câu chuyện ban đầu của chúng tôi giờ đây dường như thấp không thể tưởng tượng được: Ví dụ: bài báo ngày 01/03 về ca đầu tiên được xác nhận ở Manhattan, báo cáo rằng “hơn 80 người ở Hoa Kỳ đã được xác nhận thông qua xét nghiệm trong phòng thí nghiệm”. Chỉ năm ngày sau, một bài báo khác đưa tổng số ca được xác nhận lên hơn 300 ca.
Vào giữa tháng 3, sự phát triển bùng nổ của vi-rút đã chứng minh quá nhiều cho quy trình làm việc của chúng tôi. Bảng tính quá lớn nên truy cập chậm và các phóng viên không có đủ thời gian để báo cáo và nhập dữ liệu theo cách thủ công từ danh sách ngày càng tăng của các tiểu bang và quận của Hoa Kỳ mà chúng tôi cần theo dõi.
Cũng giống như các văn phòng (bao gồm cả văn phòng của chúng tôi) bị đóng cửa và lệnh làm việc tại nhà có hiệu lực, nhiều sở y tế trong nước bắt đầu triển khai các nỗ lực báo cáo Covid-19 lên các trang web để thông báo cho công dân tại địa phương của họ về sự lây lan tại địa phương. Chính phủ liên bang phải đối mặt với những thách thức ban đầu trong việc cung cấp một bộ dữ liệu liên bang duy nhất, đáng tin cậy.
Cơ sở dữ liệu của Times về các ca nhiễm và các ca tử vong của Covid-19 được lấy từ các trang web của hàng trăm cơ quan y tế cấp tiểu bang và quận, sử dụng kết hợp các tác vụ thủ công và tự động.
Dữ liệu địa phương có sẵn trên bản đồ, theo nghĩa đen và nghĩa bóng. Định dạng và phương pháp luận rất đa dạng tùy theo từng nơi, từ các tệp PDF thô sơ đến các trang tổng quan giàu thông tin. Ngay cả câu hỏi về điều gì đã tạo thành một "ca" cũng không thống nhất: một số nơi báo cáo các ca đã xác nhận, trong khi những nơi khác báo cáo những ca bị nghi ngờ; có những nơi lại báo cáo cả hai hoặc không có sự khác biệt.
Tại The Times, một nhóm các nhà phát triển phần mềm có trụ sở tại tòa soạn đã nhanh chóng được giao nhiệm vụ xây dựng các công cụ để tăng cường cho công việc thu thập dữ liệu hiệu quả nhất có thể.
Vào ngày 10 tháng 3 năm 2020, một ngày trước khi Tổ chức Y tế Thế giới tuyên bố virus là đại dịch, nhà phát triển tòa soạn Will Houp đã viết những dòng mã đầu tiên của một ứng dụng web dựa trên NodeJS có khả năng lấy dữ liệu Covid-19 từ một số nguồn ngày càng tăng. Chỉ trong vài ngày, Will, cùng với các đồng đội Ben Smithgall và Andrew Chavez, đã thêm các tính năng cho phép các nhà báo của chúng tôi chỉnh sửa, phê duyệt và áp dụng phép toán tùy chỉnh cho dữ liệu thu thập được.
Vào ngày 16 tháng 3, ứng dụng cốt lõi phần lớn đã hoạt động, nhưng thư mục quét trống. Để giải quyết nỗ lực khổng lồ này, chúng tôi đã tuyển dụng các nhà phát triển từ khắp nơi, nhiều người không có kinh nghiệm về tòa soạn, tạm thời mời họ viết mẩu tin lưu niệm.
Vào cuối tháng 4, chúng tôi đã lập trình thu thập số liệu từ tất cả 50 tiểu bang, gần 200 quận và nhiều mã ZIP, vùng điều tra dân số và thành phố. Đại dịch, độ phức tạp mã và cơ sở dữ liệu của chúng tôi dường như đang mở rộng theo cấp số nhân, điều này làm dấy lên những lo ngại về kiến trúc hệ thống trên một số khía cạnh.
Chúng tôi đã sớm nhận ra rằng các công cụ thu thập dữ liệu cần phải làm riêng biệt cho từng trang: chúng sẽ bị lỗi khi trang web nguồn thay đổi hoặc không phản hồi, thông báo cho chúng tôi để nhóm của chúng tôi có thể tìm ra vấn đề là do mã của chúng tôi hay do các thay đổi của trang web nguồn. Trong những ngày đầu của đại dịch, một vài trang web đáng chú ý đã thay đổi nhiều lần chỉ trong vài tuần, điều đó có nghĩa là chúng tôi phải viết lại mã của mình nhiều lần.
Giữa thay đổi liên tục của các trang và một danh sách dường như không bao giờ kết thúc về các trang web mục tiêu mới, đã đến lúc cần có nhân viên thực sự. Chúng tôi cần những nhà phát triển tận tâm, những người có thể tập trung toàn bộ sự chú ý của họ vào dự án, cho phép họ không chỉ duy trì bộ quét mà còn xây dựng ứng dụng cốt lõi và làm cho bộ quét gọn gàng hơn, có thể kiểm tra và phát triển nhanh hơn.
Từ giữa tháng 6 năm 2020 trở đi, chúng tôi đã bố trí nhân viên của nhóm thu thập thông tin với khoảng sáu nhà phát triển tại bất kỳ thời điểm nào, hầu hết đều có kinh nghiệm báo chí và dữ liệu trước đó. Nhóm thu thập thông tin là một phần quan trọng trong dự án theo dõi Covid-19 của tòa soạn, cuối cùng thu hút hơn 100 nhà báo và kỹ sư từ khắp The Times.
Có tới 50 người ngoài nhóm thu thập đã tích cực tham gia vào việc quản lý và xác minh dữ liệu chúng tôi thu thập hàng ngày. Một số dữ liệu vẫn được nhập bằng tay và tất cả dữ liệu đều được các phóng viên và nhà nghiên cứu xác minh thủ công. Đây là hoạt động kéo dài bảy ngày một tuần kể từ tháng 3 năm 2020.
Ngoài việc xuất bản dữ liệu lên trang web của The Times, chúng tôi đã cung cấp công khai bộ dữ liệu của mình trên GitHub vào cuối tháng 3 năm 2020 để mọi người sử dụng.
Đợt bùng phát Covid-19 là một thách thức chưa từng có đối với các quan chức địa phương trong việc thu thập và trình bày thông tin sức khỏe cộng đồng một cách nhanh chóng. Khi những người bên ngoài hy vọng tổng hợp và tự động hóa dữ liệu này, chúng tôi đã theo dõi trong thời gian thực khi các sở y tế trên toàn quốc tranh giành nhau để đưa các trang web lên.
Khi nỗ lực tìm hiểu về Covid-19 của chúng tôi ngày càng phát triển, các nhà phát triển phần mềm tòa soạn của chúng tôi đã đạt được sự thông thạo về chủ đề này không kém gì các phóng viên của The Times. Chúng tôi được tin tưởng và dự kiến sẽ thực hiện đánh giá tin tức hàng ngày, đặt ra những câu hỏi hóc búa: Trang nào trên trang web của tiểu bang có số liệu gần đây nhất và rõ ràng nhất về mặt phương pháp luận? Những số liệu có nghĩa là gì? Chúng tôi nghĩ rằng các quan chức đang làm toán mà chúng tôi có thể thiết kế đối chiếu và xác nhận? Chúng tôi có nên liên hệ với tiểu bang hoặc quận để xác nhận thông tin chi tiết không?
Trong khi đó, mục tiêu của chúng tôi liên tục thay đổi.
Trong tất cả, ngoại trừ một số ít trường hợp, các trang web trong vài tháng đầu tiên liên tục được chỉnh sửa, đòi hỏi chúng tôi phải liên tục chỉnh sửa và viết lại. Nhìn chung, chúng tôi đã thấy một mô hình các trang web chuyển đổi từ các bản trình bày thô sơ hơn - như PDF, bảng được chỉnh sửa thủ công hoặc mô tả văn bản dạng tự do của số trường hợp - sang trang tổng quan giàu tính năng, thường được xây dựng bằng các công cụ thông minh từ các nhà cung cấp lớn như ArcGIS, Tableau và Power BI của Microsoft.
Chúng tôi đã chứng kiến hàng trăm sở y tế nâng cấp các bản trình bày của họ về dữ liệu phức tạp, về địa lý và sức khỏe cộng đồng trong nhiều tuần và nhiều tháng.