(ONECMS) - Để tạo ra một thuật toán cá nhân hóa toàn diện hơn, NYTimes đã xây dựng một mô hình học máy dựa trên nội dung bài báo và sở thích của độc giả.




Bài viết được BBT Blog ONECMS lược dịch từ bài viết của Joyce Xu - học Khoa học máy tính và Lịch sử tại Đại học Stanford, Thực tập sinh Khoa học Dữ liệu tại Nhóm Thuật toán Gợi ý của The New York Times. Từ "chúng tôi" ở trong bài có nghĩa là đang nói đến NYTimes.
Nếu bạn tạo một tài khoản trên The New York Times, bạn sẽ thấy một danh sách các sở thích phổ biến mà bạn có thể chọn để theo dõi. Đó là một ý tưởng đơn giản: hãy cho chúng tôi biết bạn quan tâm đến điều gì và chúng tôi sẽ giới thiệu những câu chuyện trong bản tin email và trong một số phần nhất định của ứng dụng và trang web của chúng tôi.
Từ quan điểm kỹ thuật, việc thực thi ý tưởng đó ít đơn giản hơn. Nếu bạn chọn theo đuổi những sở thích như đổi mới sáng tạo, giáo dục hoặc văn hóa, chúng tôi cần biết liệu một câu chuyện nhất định có phù hợp với một trong những sở thích đó hay không.
Trước đây, chúng tôi xác định xem một bài báo có thuộc sở thích hay không bằng cách truy vấn nhãn (tag) được phóng viên, biên tập viên đính kèm vào bài báo đó.
Hệ thống phân loại của chúng tôi bao gồm hàng nghìn từ khóa, từ rộng đến siêu cụ thể, được sắp xếp theo thứ bậc (nhãn cha "Thực phẩm" có "Hải sản", cũng như "Lễ hội rượu và ẩm thực South Beach" là các từ khóa con). Một số nhãn được sử dụng thường xuyên, trong khi những nhãn khác chỉ được sử dụng một hoặc hai lần. Một số bài báo được gắn nhiều nhãn, trong khi những bài khác chỉ có một vài nhãn (Ở Việt Nam, các ông phóng viên thường lười gắn từ khóa lắm :D).
Mặc dù các nhãn đại diện cho dữ liệu ngữ nghĩa có giá trị về các chủ thể trong một câu chuyện, nhưng các truy vấn để quản lý chúng đã gặp phải các vấn đề:
Sở thích có thể không tương ứng với các nhãn cho các bài báo. Trong những trường hợp như vậy, truy vấn phải mang tính tương đối và phải xâu chuỗi nhiều nhãn có liên quan lại với nhau, với danh sách các mục ngày càng tăng để bao gồm hoặc loại trừ. Ví dụ: không có nhãn duy nhất cho sở thích “Cha mẹ và gia đình”, mà thay vào đó là nhiều nhãn liên quan khác. Tại thời điểm viết bài này, truy vấn cho "Cha mẹ và gia đình" cho ra hơn một trăm nhãn khác nhau.
Viết truy vấn yêu cầu kiến thức về cách các nhãn được áp dụng và cách chúng được sử dụng theo thời gian. Nguyên tắc gắn nhãn các bài báo của Times có từ năm 1851 và yêu cầu các bài báo được gắn nhãn càng cụ thể càng tốt. Ví dụ, để truy vấn tất cả nội dung phim, người ta cần biết rằng từ năm 1906–2013 các bài báo về phim đã được gắn nhãn “Motion Pictures”; bây giờ chúng tôi sử dụng “Phim”.
Các nhãn đại diện cho một chủ đề theo nghĩa đen, trong khi sở thích thường thể hiện một cách diễn giải sắc thái về chủ đề đó dựa trên ngữ cảnh. Ví dụ: "Trẻ em" là một trong những nhãn thành phần cung cấp sự quan tâm của "Cha mẹ và gia đình". Tuy nhiên, nhiều câu chuyện có trẻ em lại thuộc một chủ đề khác, chẳng hạn như câu chuyện tin tức về những đứa trẻ chạy trốn khỏi cuộc xung đột ở vùng Tigray của Ethiopia. Mặc dù câu chuyện đó tập trung vào trẻ em, nhưng nó không phù hợp với chủ đề về nuôi dạy con cái.
Các thuật toán gợi ý - Nhóm mà tôi đã thực tập trong học kỳ vừa qua - tin rằng có một cách tốt hơn. Chúng tôi nghĩ rằng nếu chúng tôi có thể tự động phát hiện xem một bài báo có phù hợp với sở thích hay không bằng cách đọc văn bản bài viết, chúng tôi có thể loại bỏ những truy vấn rườm rà này.
Trong nhiều năm, Nhóm Thuật toán gợi ý đã áp dụng nhiều mô hình xử lý ngôn ngữ tự nhiên khác nhau để xếp hạng và đề xuất nội dung có liên quan.
Một trong những thuật toán đề xuất lâu đời nhất của chúng tôi dựa trên Latent Dirichlet Allocation, hoặc LDA, mô hình hóa mỗi bài viết như một hỗn hợp các “chủ đề” cơ bản. Để quyết định có nên giới thiệu một bài báo cho độc giả hay không, chúng tôi so sánh sự phân bổ các chủ đề trong lịch sử đọc của độc giả với sự phân bổ các chủ đề trong bài viết. Chúng tôi gọi các phân phối là “vectơ chủ đề”. Vectơ chủ đề của độc giả và của bài viết càng gần nhau, thì chúng tôi càng có nhiều khả năng đề xuất bài viết.
Rất tiếc, chúng tôi không trực tiếp kiểm soát các chủ đề mà thuật toán LDA học, chỉ kiểm soát số lượng chủ đề. Trong LDA, các chủ đề được học dựa trên sự xuất hiện đồng thời của các từ trong các tài liệu. Chúng tôi không có cách nào đảm bảo rằng một trong những chủ đề này tương ứng với một trong những mối quan tâm đã thiết lập của chúng tôi - hoặc thậm chí rằng những chủ đề này hoàn toàn có thể hiểu được bởi con người.
Để phát triển bản trình bày về sở thích mà người dùng đăng ký theo dõi, chúng tôi cần một mô hình mới liên kết các bài viết với các chủ đề cụ thể mà chúng tôi chọn.
Chúng tôi đã giải quyết vấn đề này bằng cách xây dựng một mô hình học máy dự đoán sở thích dựa trên nội dung của một bài báo. Cách tiếp cận này được gọi là “phân loại nhiều nhãn” vì mỗi điểm dữ liệu (trong trường hợp của chúng tôi là một bài báo) được phân loại thành không hoặc nhiều nhãn (hoặc nhóm sở thích).
Để tạo tập dữ liệu đào tạo gồm các bài báo được ghép nối với nhãn sở thích, chúng tôi đã sử dụng các truy vấn thủ công hiện có, mặc dù chúng tôi biết chúng không hoàn hảo và thường bỏ sót các bài viết thuộc tập dữ liệu.
 |
| Một số nhãn trong tập dữ liệu này không chính xác do các truy vấn không hoàn hảo. |
Trong bảng trên, bài viết về "Cuff link" có thể được đề xuất rất hợp lý cho độc giả có sở thích về “Thời trang & Phong cách”, nhưng do truy vấn không hoàn hảo, bài viết bị thiếu nhãn chính xác. Tương tự, bài viết về mua đồ trang sức trên Instagram chỉ được gắn nhãn “Kinh doanh & Công nghệ” vì nó thiếu các nhãn liên quan để được gắn nhãn “Thời trang & Phong cách”.
Các nhãn nhiễu vẫn có thể hữu ích, miễn là mô hình không ghi nhớ và tái tạo các điểm không chính xác thường xuyên trong dữ liệu đào tạo.
Để giảm thiểu nguy cơ nhãn không chính xác ảnh hưởng quá mức đến mô hình của chúng tôi, chúng tôi ưu tiên các mô hình nhỏ, đơn giản hơn các mô hình lớn, phức tạp và chúng tôi lấy trung bình các dự đoán từ nhiều mô hình khác nhau. Chúng tôi đã sử dụng một tập hợp các mô hình hồi quy logic: mỗi mô hình tận dụng độc lập các nhãn được dự đoán trước đó của nó để giúp dự đoán nhãn tiếp theo. Cách tiếp cận này được gọi là một tập hợp các chuỗi bộ phân loại.
Vì các mô hình trình phân loại của chúng tôi tương đối đơn giản, chúng tôi đảm bảo trích xuất các bản trình bày tính năng phong phú và biểu cảm của các bài báo để các trình phân loại sử dụng. Sau nhiều vòng thử nghiệm, chúng tôi đã đưa ra bản đại diện cuối cùng với ba thành phần:
1. Một vectơ chủ đề LDA, như đã thảo luận ở trên.
2. Một vectơ dựa trên các từ khóa: các từ bất thường phổ biến trong bài viết.
3. Nhúng Universal Sentence Encoder.
Universal Sentence Encoder, hoặc USE, là một mạng nơ-ron biến văn bản đầu vào thành một vectơ biểu diễn: các văn bản gần nghĩa với nhau sẽ tạo ra các vectơ có khoảng cách gần nhau.
Để khuyến khích mô hình mã hóa kiến thức ngữ nghĩa, các nhà nghiên cứu ban đầu tại Google đã đào tạo mô hình này về các nhiệm vụ như dự đoán các câu trả lời Hỏi & Đáp hoặc suy ra các hàm ý logic. Đây là một trong số ít mô hình được thiết kế để xử lý các đầu vào dài hơn cả câu, giúp thuận tiện cho việc mã hóa các bài báo của chúng tôi.
Trong khi mô hình USE đầu tiên được đào tạo trên các tập dữ liệu lấy từ Wikipedia và các diễn đàn thảo luận trực tuyến, chúng tôi đã đào tạo lại phiên bản của mô hình trên các bài báo trên Times. Bởi vì The Times đã xuất bản báo chí trong gần 170 năm, chúng tôi có rất nhiều nội dung để cung cấp cho bộ dữ liệu của mình.
Khi chúng tôi có được các bộ nhúng này và kết hợp chúng với các vectơ từ khóa và LDA, chúng tôi áp dụng mô hình phân loại, mô hình này tạo ra điểm xác suất cho mỗi sở thích. Chúng tôi có thể thiết lập xác suất giới hạn cho mỗi sở thích và so sánh chúng với các nhãn dựa trên truy vấn để đánh giá.
Như chúng tôi đã nghi ngờ, mô hình học máy tạo ra một mạng lưới rộng hơn cho mỗi sở thích so với các truy vấn thủ công và nó trả về nhiều bài báo có liên quan hơn.
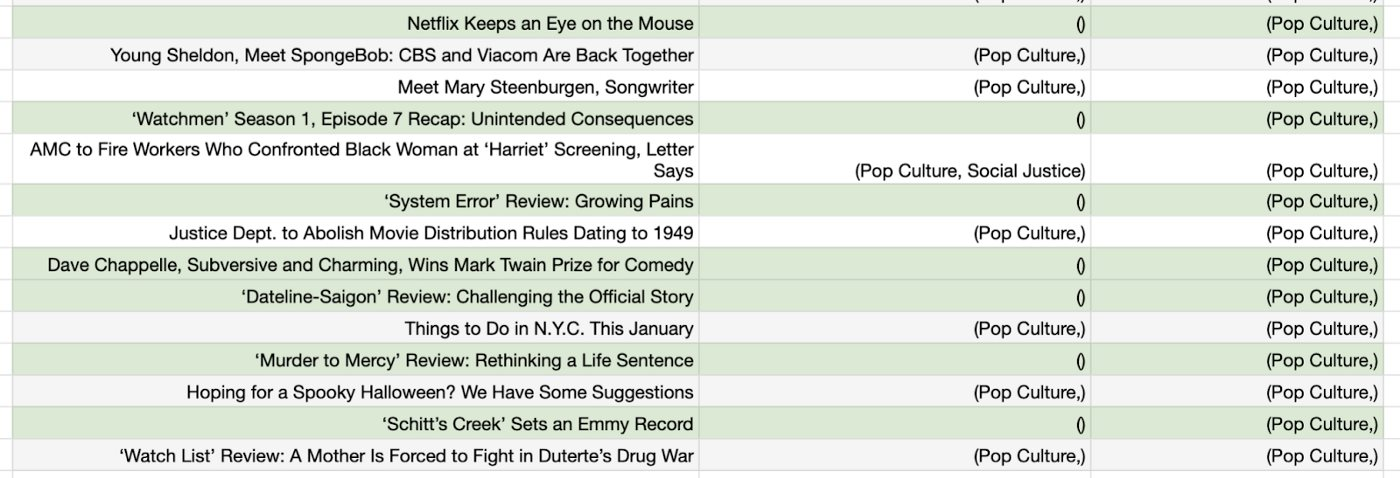 |
| Trong bảng này, cột trung tâm là danh sách các sở thích được chỉ định dựa trên các truy vấn và cột ngoài cùng bên phải là danh sách được chỉ định bởi mô hình. |
Khi xem xét kỹ hơn một số nhãn không chính xác, chúng tôi thường có thể hiểu tại sao phóng viên lại gán nhãn đó, nhưng thấy rằng việc sửa lỗi cần có sự đánh giá của con người. Cần có kiến thức về lịch sử và xã hội, cũng như khả năng nhận biết ngữ cảnh để một số bài báo phù hợp hơn với một số danh mục sở thích so với những bài báo khác.
Chúng tôi nhận ra rằng mặc dù mô hình của chúng tôi tốt hơn hệ thống dựa trên truy vấn hiện có về nhiều mặt, nhưng sẽ là vô trách nhiệm nếu để nó quản lý các sở thích mà không có sự giám sát của con người.
Độc giả tin tưởng The Times sẽ quản lý nội dung phù hợp với họ và chúng tôi coi trọng sự tin tưởng này. Thuật toán này, giống như nhiều hệ thống ra quyết định dựa trên AI khác, không nên đưa ra quyết định cuối cùng mà không có sự giám sát của con người.
Bộ phân loại sở thích này đã được sử dụng như một trong số các đầu vào mà thuật toán của chúng tôi sử dụng để tính toán các đề xuất bài viết.
Trong thời gian tới, chúng tôi dự định thiết lập quy trình làm việc liên tục của biên tập viên cộng tác với tòa soạn và kết hợp thêm thuật toán này vào các sản phẩm được cá nhân hóa của chúng tôi.
Với các thuật toán đề xuất chính xác hơn và giám sát biên tập, chúng tôi có thể mang đến cho độc giả trải nghiệm đọc tốt hơn trên nhiều nội dung mà The Times sản xuất hàng ngày.